Stop trusting green dashboards.
PingSLA tests real user flows — logins, checkouts, APIs — from multiple regions so you know when revenue is actually at risk.
- Detect broken checkout before customers do
- Catch silent JavaScript failures
- Validate real login & payment flows
- Run synthetic tests globally
- Get alerts only when it matters
No credit card required • 5-minute setup • Founder-built
This is revenue flow monitoring
We detect the failures that cost you money — not just the ones that trigger your basic health checks.
Three layers of protection
From infrastructure basics to managed enterprise monitoring — we cover every layer of your stack.
Infrastructure Monitoring
The foundation. Make sure your servers, certificates, and domains are healthy.
Flow Monitoring
The differentiator. Test actual user journeys — not just endpoints.
Managed Monitoring
Full service. We write, maintain, and monitor your flows for you.
Enterprise clients: Dedicated support, custom scripts, quarterly audits
One dashboard. Zero context-switching.
Stop jumping between CloudWatch, Slack, PagerDuty, and spreadsheets. Everything you need to detect, alert, and report — in one interface built for engineering teams.
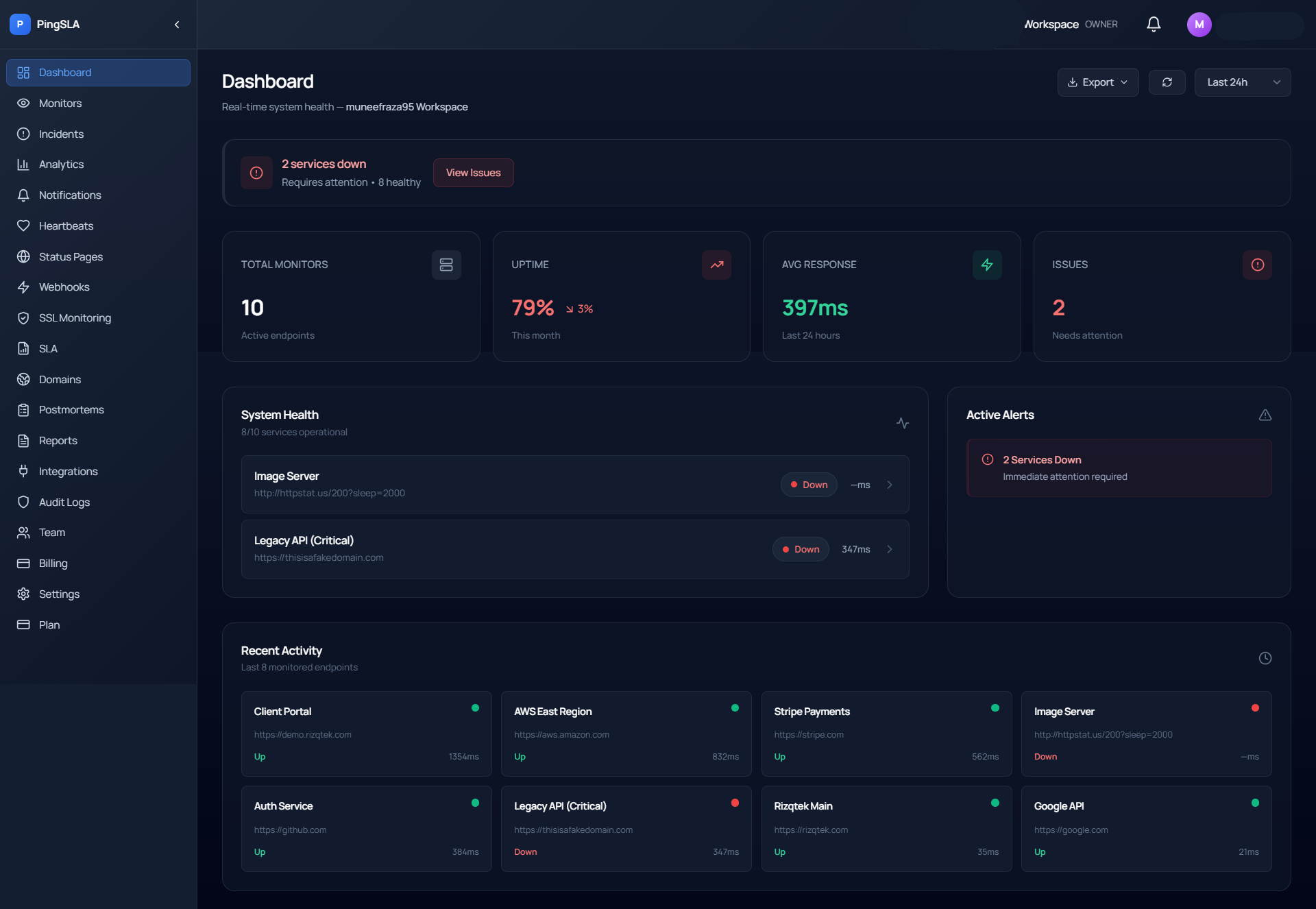
Real incident from last Tuesday
Our API went down at 2:14 AM. PingSLA detected it in the next 30-second check, sent alerts to our on-call engineer's Slack + SMS, and logged the full timeline. By 2:24 AM, we had scaled our DB connection pool and resolved the incident — before any customer support tickets came in.
API timeout detected
2:14:03 AM
us-east-1 region
Alerts sent
2:14:04 AM
Slack + SMS to 3 on-call
Sarah acknowledged
2:16:22 AM
Incident #1847 opened
Fix deployed
2:23:15 AM
DB connection pool scaled
Service recovered
2:24:01 AM
MTTR: 9m 58s
11 alerts sent in last incident
Detect in 30 seconds
8x faster detectionMulti-region health checks every 30s. Catch failures 8x faster than manual monitoring.
Alert in <1 second
Sub-second deliveryInstant routing to Slack, SMS, Discord, PagerDuty. Your team knows before your customers do.
Export SLA reports
3 hours → 10 secondsOne-click uptime reports for stakeholders. No more spreadsheet gymnastics.
Public status pages
-40% support loadAuto-updating status.yourcompany.com. Reduce support tickets by 40% during incidents.
SSL expiry warnings
Zero surprise outages30/14/7-day alerts before certs expire. Never wake up to a broken HTTPS site.
Full incident audit
Complete paper trailEvery outage logged with detection time, alert delivery, and resolution. Perfect for post-mortems.
No credit card • 30-second setup • Free tier includes 1 monitor forever
Scan thousands of sites in minutes
Bulk scanning capability for agencies, MSPs, and enterprises managing multiple client properties.
PingSLA vs. Traditional Tools
We focus on what actually breaks your revenue — not vanity metrics.
| Feature | PingSLA | Datadog | UptimeRobot | BetterStack |
|---|---|---|---|---|
| Flow Monitoring | ||||
| Checkout Testing | ||||
| Login Validation | ||||
| JS Error Capture | ||||
| Multi-step Flows | ||||
| Basic Uptime | ||||
| SSL Monitoring |
Uptime tools tell you the server is responding. We tell you if your revenue is flowing.
Monitoring is step one.
Auto-remediation is next.
The PingSLA Ops Engine goes beyond alerting — it detects, diagnoses, and resolves incidents automatically, so your team responds to reports, not pages.
Detect Failure
Multi-region checks identify the outage pattern and severity in real-time.
Run Recovery
Pre-configured playbooks execute automatically — restart services, scale pods, failover DNS.
Notify Team
Full incident report sent to your team with root cause, actions taken, and resolution status.
Try our free tools right now
Don't take our word for it — test your own site. Run a complete health check, test your login, validate checkout flows, or check any API endpoint. No signup required.
Infrastructure Audit
PopularComplete site health check: SSL, DNS, security headers, performance — in 60 seconds.
Login Tester
Test any login page from 3 global regions. Get screenshot & full analysis.
Checkout Tester
Validate checkout flows end-to-end. Catch broken carts before customers leave.
API Tester
Test any API endpoint. Check status, response time, headers & body validation.
Built by founders who've felt the pain
Founder-Built
Created by engineers who've been woken up by broken checkouts at 3am.
Used by Agencies
Trusted by agencies managing hundreds of client sites and portfolios.
Battle-Tested
Built from real incidents. Every feature exists because something broke.
Know when your revenue breaks. Not just your server.
Stop trusting green dashboards. Start monitoring what actually matters — the flows that generate your revenue.
No credit card required • 5-minute setup • Cancel anytime